首頁
娛樂
體育
汽車
科技
育兒
歷史
美食
數碼
時尚
寵物
收藏
教育
財經
社會
國際
選單
首頁
娛樂
體育
汽車
科技
育兒
歷史
美食
數碼
時尚
寵物
收藏
教育
財經
社會
國際
首頁
>
標簽
>attention
catch
your
attention
especially
discuss
catch ones attention造句?
Especially discuss things that have her interest and surely will catch your attention...
體育
2022-11-28
attention
block
sequence
計算
Model
Attention Model for Online Decoding of 語音識別
Attention Model中也使用block(分塊)的方式來解決這一的問題[3],每個block輸出對應的yb,其中每個block結尾會輸出一個作為這個block的結束,具體方式如下:首先把長度為T的序列分成長度為W的block,這樣b...
娛樂
2017-12-18
變換
模型
重複
放大
attention
我們可以無損放大一個Transformer模型嗎?
然而像BERT這樣的模型,它是內積之後除了個再做Softmax的,,而一旦放大模型後,除以變成了除以,內積不變也不能保持Attention矩陣不變,而應當還需要往q,k的權重分別再乘個,所以最終的變換應該是:經過這樣變換後,Attentio...
娛樂
2021-06-05
Sagan
影象
gan
attention
卷積
Ian Goodfellow等提出自注意力GAN,ImageNet影象合成獲最優結果!
谷歌大腦的Ian Goodfellow等人在他們的最新研究中提出“自注意力生成對抗網路”(SAGAN),將自注意力機制引入到卷積GAN中,作為卷積的補充,在ImageNet多類別影象合成任務中取得了最優的結果...
娛樂
2018-05-24
attention
tensor
點積
維度
矩陣
扒原始碼:跳出self-attention看多頭點積注意力
因此,Q 和 K 在計算 attenion 分數時,實際上進行了 B × N 次的二維矩陣點積,最終的輸出矩陣是:score - [B, N, F, T]請注意,關於多頭,實際上就是在 attention 之前,拆分出一個 N 的維度,把原...
娛樂
2021-06-27
向量
attention
輸入
我們
Transformer+self-attention超詳解(亦個人心得)
2 計算公式詳解有些突兀,不著急,接下來我們看看self-attention的公式長什麼樣子:公式1此公式在論文《attention is all your need》中出現,拋開Q、K、V與dk不看,則最開始的self-attention...
娛樂
2021-11-13
size
attention
layer
LENGTH
seq
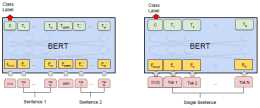
小白Bert系列-原始碼解析-modeling.py
reshape(position_embeddings,position_broadcast_shape)output+=position_embeddings#進行layer norm和dropoutoutput=layer_norm_a...
娛樂
2020-06-07
attention
VQA
head
Oracle
question
2021 CVPR | VQA論文速遞
法國小哥的口語聽著腦袋糊,大家還是看原文吧,個人覺得這篇原文值得一看)keywords: language bias, infrequent answers,VL-Transformer, visual oracle, reasoning,...
娛樂
2021-06-17
attention
細粒度
分類
Maps
演算法
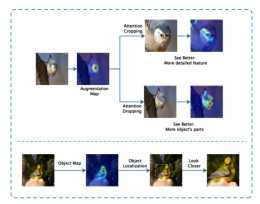
細粒度分類網路之WS-DAN論文閱讀附程式碼
Attention Cropping &...
娛樂
2019-07-14
演算法
attention
learning
訓練
encoder
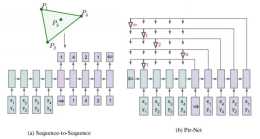
深度強化學習-求解組合最佳化問題
針對於有監督訓練中訓練資料獲取困難、精度不足的問題,Bello等使用Actor Critc強化學習演算法對PN進行訓練,在節點長度n=100的TSP問題上獲得了近似最優解路徑長度為:Actor-Critic演算法:Policy gradie...
娛樂
2019-12-10
Entity
relational
attention
DRL
policy
上下求索---Relational Deep Reinforcement Learning筆記
隱式地將relational引入NN結構中解決方案:將問題編碼成一個二維輸入,然後對於輸入做變換,成為N個entity,對於這N個entity採用multi-head dot-product attention (MHDPA)來表示enti...
娛樂
2018-06-15
sentence
Word
Level
Document
attention
《Neural Sentiment Classification with User and Product Attention》閱讀筆記
二、在不同語義級別中引入user和product的資訊主要思想:不同的word對於表達句子含義的貢獻應該是不一樣的,上述建模過程中由LSTM的隱層狀態到上一級語義表示過程採用的average pooling相當於是每個word(senten...
娛樂
2016-09-26
節點
Self
attention
向量
注意力
【Arxiv】 GKAT: Graph Kernel Attention Transformers 為線性注意力加上圖結構先驗
當線性注意力不再計算, 同時也無法得到基於語義的鄰接矩陣,這篇文章的思路是把節點的結構向量的點積作為圖先驗知識...
娛樂
2021-07-19
hidden
attention
States
輸出
output
快速掌握BERT原始碼(pytorch)
BertOutputforword 函式接收 引數 :hidden_states(由BertSelfAttention輸出), input_tensor(就是BertAttention的input_tensor,也就是BertSelfAtt...
娛樂
2019-08-14
attention
Self
Model
序列
transformer
Pytorch_Transformer框架
Transformer框架最核心的改進是在序列處理問題中放棄了迴圈網路RNN和CNN模型,使用注意力Attention演算法計算序列中各個元素之間的關係...
娛樂
2019-12-25
Mask
Self
attention
padding
key
PyTorch的Transformer
4,decodertransformer中的decoder棧是由6個相同的decoder layer組成的,和encoder layer由2個sub-layer組成不同,每個decoder layer是由3個sub-layer組成的,分別是...
娛樂
2021-08-13
attention
答案
https
github
com
答案解析(1)—史上最全Transformer面試題:靈魂20問幫你徹底搞定Transformer
更具體的結果,大家可以看一下實驗圖(從蓮子同學那裡看到的,專門去看了一下論文):4.為什麼在進行softmax之前需要對attention進行scaled(為什麼除以dk的平方根),並使用公式推導進行講解答案解析參考這裡:transform...
娛樂
2020-06-21
inductive
BIAS
Self
attention
CNN
關於Vision Transformer的一些思考
然後我們繞了個大圈又回到了幾十年前的MLP:CNN和RNN的提出本來是將領域的知識作為inductive bias,融入到MLP之中,以加速深度學習在CV和NLP等特定領域的落地,我們現在資料量大了,計算資源強了,錢包鼓了,桌子一掀——要什...
娛樂
2020-11-06
MFB
MLB
attention
MCB
question
《Multi-modal Factorized Bilinear Pooling with Co-Attention Learning for VQA》論文筆記
為了解決這些問題,提出了multi-modal Factorized Bilinear pooling(MFB),既有MLB的較低的輸出特徵維度,又有MCB的較強表達能力...
娛樂
2018-06-01
1
2
3
»
搜索
熱門標籤
大渝
公深
率來
香梅
牛健子
granulatus
Heisthetallestofalltheboystudent
solace
nx260
張曉紅版
漢均
750Li
day16
李九霖
賣鍾
從炎
越淡
班娜
芙蕾達
變潤