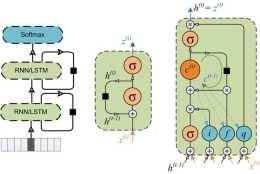
介紹
上一節在《迴圈神經網路——實現LSTM》中介紹了迴圈神經網路目前最流行的實現方法LSTM和GRU,這一節就演示如何利用Tensorflow來搭建LSTM網路。
程式碼LV1是指本次的演示是最核心的code,並沒有多餘的功能。
為了更深刻的理解LSTM的結構,這次所用的並非是tensorflow自帶的rnn_cell類,而是從新編寫,並且用scan來實現graph裡的loop (動態RNN)。
任務描述:
這次所要學習的模型依然是程式碼演示LV3中的用聲音來預測口腔移動,沒有閱讀的朋友請先閱讀連結中的章節對於任務的描述。同時拿連結中的前饋神經網路與迴圈神經網路進行比較。
處理訓練資料
目的:減掉每句資料的平均值,除以每句資料的標準差,降低模型擬合難度。
程式碼:
# 所需庫包
import tensorflow as tf
import numpy as np
import time
import matplotlib。pyplot as plt
%matplotlib inline
# 直接使用在程式碼演示LV3中定義的function
def Standardize(seq):
#subtract mean
centerized=seq-np。mean(seq, axis = 0)
#divide standard deviation
normalized=centerized/np。std(centerized, axis = 0)
return normalized
# 讀取輸入和輸出資料
mfc=np。load(‘X。npy’)
art=np。load(‘Y。npy’)
totalsamples=len(mfc)
# 20%的資料作為validation set
vali_size=0。2
# 將每個樣本的輸入和輸出資料合成list,再將所有的樣本合成list
# 其中輸入資料的形狀是[n_samples, n_steps, D_input]
# 其中輸出資料的形狀是[n_samples, D_output]
def data_prer(X, Y):
D_input=X[0]。shape[1]
data=[]
for x,y in zip(X,Y):
data。append([Standardize(x)。reshape((1,-1,D_input))。astype(“float32”),
Standardize(y)。astype(“float32”)])
return data
# 處理資料
data=data_prer(mfc, art)
# 分訓練集與驗證集
train=data[int(totalsamples*vali_size):]
test=data[:int(totalsamples*vali_size)]
示意圖:1,2,3,4,5表示list中的每個元素,而每個元素又是一個長度為2的list。

解釋:比如全部資料有100個序列,如果設定每個input的形狀就是[1, n_steps, D_input],那麼處理後的list的長度就是100,這樣的資料使用的是SGD的更新方式。而如果想要使用mini-batch GD,將batch size(也就是n_samples)的個數為2,那麼處理後的list的長度就會是50,每次網路訓練時就會同時計算2個樣本的梯度並用均值來更新權重。 因為每句語音資料的時間長短都不相同,如果使用3維tensor,需要大量的zero padding,所以將n_samples設成1。但是這樣處理的缺點是:只能使用SGD,無法使用mini-batch GD。如果想使用mini-batch GD,需要幾個n_steps長度相同的樣本並在一起形成3維tensor(不等長時需要zero padding,如下圖)。
演示圖:v表示一個維度為39的向量,序列1的n_steps的長度為3,序列2的為7,如果想把這三個序列併成3維tensor,就需要選擇最大的長度作為n_steps的長度,將不足該長度的序列補零(都是0的39維的向量)。最後會形成shape為[3,7,39]的一個3維tensor。

權重初始化方法
目的:合理的初始化權重,可以降低網路在學習時卡在鞍點或極小值的損害,增加學習速度和效果
程式碼:
def weight_init(shape):
initial = tf。random_uniform(shape,minval=-np。sqrt(5)*np。sqrt(1。0/shape[0]), maxval=np。sqrt(5)*np。sqrt(1。0/shape[0]))
return tf。Variable(initial,trainable=True)
# 全部初始化成0
def zero_init(shape):
initial = tf。Variable(tf。zeros(shape))
return tf。Variable(initial,trainable=True)
# 正交矩陣初始化
def orthogonal_initializer(shape,scale = 1。0):
#https://github。com/Lasagne/Lasagne/blob/master/lasagne/init。py
scale = 1。0
flat_shape = (shape[0], np。prod(shape[1:]))
a = np。random。normal(0。0, 1。0, flat_shape)
u, _, v = np。linalg。svd(a, full_matrices=False)
q = u if u。shape == flat_shape else v
q = q。reshape(shape) #this needs to be corrected to float32
return tf。Variable(scale * q[:shape[0], :shape[1]],trainable=True, dtype=tf。float32)
def bias_init(shape):
initial = tf。constant(0。01, shape=shape)
return tf。Variable(initial)
# 洗牌
def shufflelists(data):
ri=np。random。permutation(len(data))
data=[data[i] for i in ri]
return data
解釋:其中shufflelists是用於洗牌重新排序list的。正交矩陣初始化是有利於gated_rnn的學習的方法。
定義LSTM類
屬性:使用class類來定義是因為LSTM中有大量的引數,定義成屬性方便管理。
程式碼:在init中就將所有需要學習的權重全部定義成屬性
class LSTMcell(object):
def __init__(self, incoming, D_input, D_cell, initializer, f_bias=1。0):
# var
# incoming是用來接收輸入資料的,其形狀為[n_samples, n_steps, D_input]
self。incoming = incoming
# 輸入的維度
self。D_input = D_input
# LSTM的hidden state的維度,同時也是memory cell的維度
self。D_cell = D_cell
# parameters
# 輸入門的 三個引數
# igate = W_xi。* x + W_hi。* h + b_i
self。W_xi = initializer([self。D_input, self。D_cell])
self。W_hi = initializer([self。D_cell, self。D_cell])
self。b_i = tf。Variable(tf。zeros([self。D_cell]))
# 遺忘門的 三個引數
# fgate = W_xf。* x + W_hf。* h + b_f
self。W_xf = initializer([self。D_input, self。D_cell])
self。W_hf = initializer([self。D_cell, self。D_cell])
self。b_f = tf。Variable(tf。constant(f_bias, shape=[self。D_cell]))
# 輸出門的 三個引數
# ogate = W_xo。* x + W_ho。* h + b_o
self。W_xo = initializer([self。D_input, self。D_cell])
self。W_ho = initializer([self。D_cell, self。D_cell])
self。b_o = tf。Variable(tf。zeros([self。D_cell]))
# 計算新資訊的三個引數
# cell = W_xc。* x + W_hc。* h + b_c
self。W_xc = initializer([self。D_input, self。D_cell])
self。W_hc = initializer([self。D_cell, self。D_cell])
self。b_c = tf。Variable(tf。zeros([self。D_cell]))
# 最初時的hidden state和memory cell的值,二者的形狀都是[n_samples, D_cell]
# 如果沒有特殊指定,這裡直接設成全部為0
init_for_both = tf。matmul(self。incoming[:,0,:], tf。zeros([self。D_input, self。D_cell]))
self。hid_init = init_for_both
self。cell_init = init_for_both
# 所以要將hidden state和memory並在一起。
self。previous_h_c_tuple = tf。stack([self。hid_init, self。cell_init])
# 需要將資料由[n_samples, n_steps, D_cell]的形狀變成[n_steps, n_samples, D_cell]的形狀
self。incoming = tf。transpose(self。incoming, perm=[1,0,2])
解釋:將hidden state和memory並在一起,以及將輸入的形狀變成[n_steps, n_samples, D_cell]是為了滿足tensorflow中的scan的特點,後面會提到。
每步計算方法:定義一個function,用於制定每一個step的計算。
程式碼:
def one_step(self, previous_h_c_tuple, current_x):
# 再將hidden state和memory cell拆分開
prev_h, prev_c = tf。unstack(previous_h_c_tuple)
# 這時,current_x是當前的輸入,
# prev_h是上一個時刻的hidden state
# prev_c是上一個時刻的memory cell
# 計算輸入門
i = tf。sigmoid(
tf。matmul(current_x, self。W_xi) +
tf。matmul(prev_h, self。W_hi) +
self。b_i)
# 計算遺忘門
f = tf。sigmoid(
tf。matmul(current_x, self。W_xf) +
tf。matmul(prev_h, self。W_hf) +
self。b_f)
# 計算輸出門
o = tf。sigmoid(
tf。matmul(current_x, self。W_xo) +
tf。matmul(prev_h, self。W_ho) +
self。b_o)
# 計算新的資料來源
c = tf。tanh(
tf。matmul(current_x, self。W_xc) +
tf。matmul(prev_h, self。W_hc) +
self。b_c)
# 計算當前時刻的memory cell
current_c = f*prev_c + i*c
# 計算當前時刻的hidden state
current_h = o*tf。tanh(current_c)
# 再次將當前的hidden state和memory cell並在一起返回
return tf。stack([current_h, current_c])
解釋:將上一時刻的hidden state和memory拆開,用於計算後,所出現的新的當前時刻的hidden state和memory會再次並在一起作為該function的返回值,同樣是為了滿足scan的特點。定義該function後,LSTM就已經完成了。one_step方法會使用LSTM類中所定義的parameters與當前時刻的輸入和上一時刻的hidden state與memory cell計算當前時刻的hidden state和memory cell。
scan:使用scan逐次迭代計算所有timesteps,最後得出所有的hidden states進行後續的處理。
程式碼:
def all_steps(self):
# 輸出形狀 : [n_steps, n_sample, D_cell]
hstates = tf。scan(fn = self。one_step,
elems = self。incoming, #形狀為[n_steps, n_sample, D_input]
initializer = self。previous_h_c_tuple,
name = ‘hstates’)[:,0,:,:]
return hstates
解釋:scan接受的fn, elems, initializer有以下要求:
fn:第一個輸入是上一時刻的輸出(需要與fn的返回值保持一致),第二個輸入是當前時刻的輸入。
elems:scan方法每一步都會沿著所要處理的tensor的第一個維進行一次一次取值,所以要將資料由[n_samples, n_steps, D_cell]的形狀變成[n_steps, n_samples, D_cell]的形狀。
initializer:初始值,需要與fn的第一個輸入和返回值保持一致。
scan的返回值在上例中是[n_steps, 2, n_samples, D_cell],其中第二個維度的2是由hidden state和memory cell組成的。
構建網路
程式碼:
D_input = 39
D_label = 24
learning_rate = 7e-5
num_units=1024
# 樣本的輸入和標籤
inputs = tf。placeholder(tf。float32, [None, None, D_input], name=“inputs”)
labels = tf。placeholder(tf。float32, [None, D_label], name=“labels”)
# 例項LSTM類
rnn_cell = LSTMcell(inputs, D_input, num_units, orthogonal_initializer)
# 呼叫scan計算所有hidden states
rnn0 = rnn_cell。all_steps()
# 將3維tensor [n_steps, n_samples, D_cell]轉成 矩陣[n_steps*n_samples, D_cell]
# 用於計算outputs
rnn = tf。reshape(rnn0, [-1, num_units])
# 輸出層的學習引數
W = weight_init([num_units, D_label])
b = bias_init([D_label])
output = tf。matmul(rnn, W) + b
# 損失
loss=tf。reduce_mean((output-labels)**2)
# 訓練所需
train_step = tf。train。AdamOptimizer(learning_rate)。minimize(loss)
解釋:以hard coding的方式直接構建一個網路,輸入是39維,第一個隱藏層也就是RNN-LSTM,1024維,而輸出層又將1024維的LSTM的輸出變換到24維與label對應。
注: 這個網路並不僅僅取序列的最後一個值,而是要用所有timestep的值與實際軌跡進行比較計算loss
訓練網路
程式碼:
# 建立session並實際初始化所有引數
sess = tf。InteractiveSession()
tf。global_variables_initializer()。run()
# 訓練並記錄
def train_epoch(EPOCH):
for k in range(EPOCH):
train0=shufflelists(train)
for i in range(len(train)):
sess。run(train_step,feed_dict={inputs:train0[i][0],labels:train0[i][1]})
tl=0
dl=0
for i in range(len(test)):
dl+=sess。run(loss,feed_dict={inputs:test[i][0],labels:test[i][1]})
for i in range(len(train)):
tl+=sess。run(loss,feed_dict={inputs:train[i][0],labels:train[i][1]})
print(k,‘train:’,round(tl/83,3),‘test:’,round(dl/20,3))
t0 = time。time()
train_epoch(10)
t1 = time。time()
print(“ %f seconds” % round((t1 - t0),2))
# 訓練10次後的輸出和時間
(0, ‘train:’, 0。662, ‘test:’, 0。691)
(1, ‘train:’, 0。558, ‘test:’, 0。614)
(2, ‘train:’, 0。473, ‘test:’, 0。557)
(3, ‘train:’, 0。417, ‘test:’, 0。53)
(4, ‘train:’, 0。361, ‘test:’, 0。504)
(5, ‘train:’, 0。327, ‘test:’, 0。494)
(6, ‘train:’, 0。294, ‘test:’, 0。476)
(7, ‘train:’, 0。269, ‘test:’, 0。468)
(8, ‘train:’, 0。244, ‘test:’, 0。452)
(9, ‘train:’, 0。226, ‘test:’, 0。453)
563。110000 seconds
解釋:由於上文的LSTM是非常直接的編寫方式,並不高效,在實際使用中會花費較長時間。
預測效果
程式碼:pY=sess。run(output,feed_dict={inputs:test[10][0]})
plt。plot(pY[:,8])
plt。plot(test[10][1][:,8])
plt。title(‘test’)
plt。legend([‘predicted’,‘real’])
解釋:plot出一個樣本中的維度的預測效果與真是軌跡進行對比
效果圖:


總結說明
該文是儘可能只展示LSTM最核心的部分(只訓練了10次,有興趣的朋友可以自己多訓練幾次),幫助大家理解其工作方式而已,完整程式碼可以從我的github中LSTM_lV1中找到。
該LSTM由於執行效率並不高,下一篇會稍微進行改動加快執行速度,並整理結構方便使用GRU以及多層RNN的堆疊以及雙向RNN,同時加入其他功能。